
If you’re wanting to test out your query tuning skills, download a Stack Overflow database and check out https://data.stackexchange.com/stackoverflow/queries for example queries. I like to choose a random query and see how well I can optimize it. Sometimes that means adding an index. Sometimes that means rewriting the query altogether. There’s not a “right” answer so it’s really up to you how far down the rabbit hole you feel like going. Let’s pick a query and see what we can learn.
And the Winner Is…
I went to https://data.stackexchange.com/stackoverflow/queries and after clicking around a bit, I landed on this query submitted by the user brucestayhungry:
https://data.stackexchange.com/stackoverflow/query/1360210/select-all-master-answers-in-one-week
I adjusted the date ranges to match up with the Stackoverflow2013 database I have restored. We’ll turn on statistics IO/time, make sure we include the actual execution plan, and execute the query:
SELECT pl.CreationDate, ma.*
FROM PostLinks pl
JOIN Posts as ma ON ma.ParentId = pl.RelatedPostId
WHERE pl.LinkTypeId = 3
AND ma.PostTypeId = 2
AND pl.CreationDate > '2013-09-13 00:00:00'
AND pl.CreationDate < '2013-09-20 00:00:00'
ORDER BY pl.CreationDate DESC;
GO
That took awhile. So that we have a baseline, let’s plug the stats information into Statistics Parser.
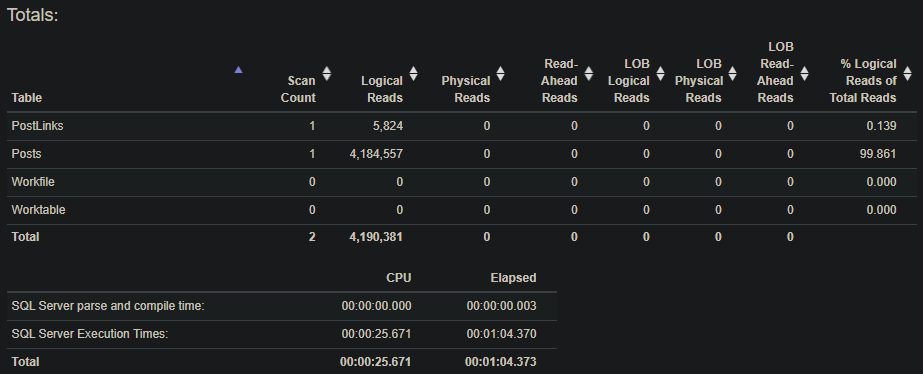
There’s plenty to digest with the execution plan:
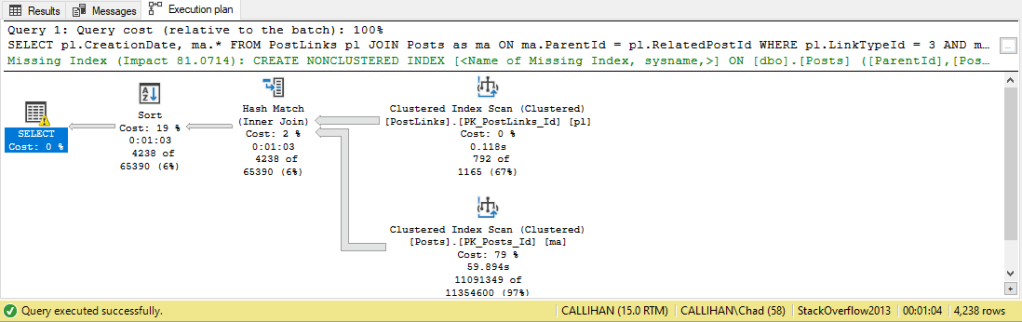
We have a few clustered index scans, joining the results together, and sorting the results. We have a yellow exclamation point over our SELECT. Hovering over the icon we can see this is due to an ExcessiveGrant warning for memory:
May I Suggest
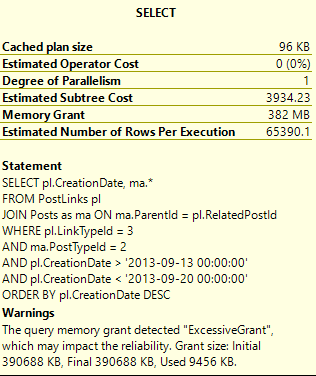
You may have noticed that we have a suggested index. The suggested index is for the Posts table and is quite large:
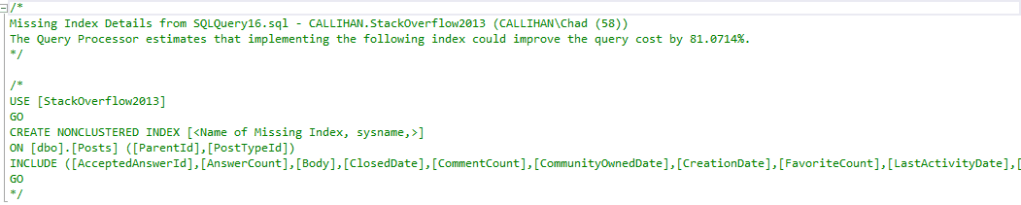
That does not look appealing at all. With so many columns involved and the amount of data that would be involved in creating/maintaining it, I’m not going to consider that index right now. We’ll expect a key lookup later in our plan.
Start Small
Let’s start with the smaller table of the two which is the first index scan we see in the execution plan. What can we do for the PostLinks table? We have RelatedPostId used in the JOIN plus CreationDate and LinkTypeId in our WHERE clause. Should we try something like this?
CREATE INDEX IX_RelatedPostId_LinkTypeId_CreationDate ON PostLinks (
RelatedPostId
,LinkTypeId
,CreationDate
);
We’ll create that index and run our query again. That results in the following:
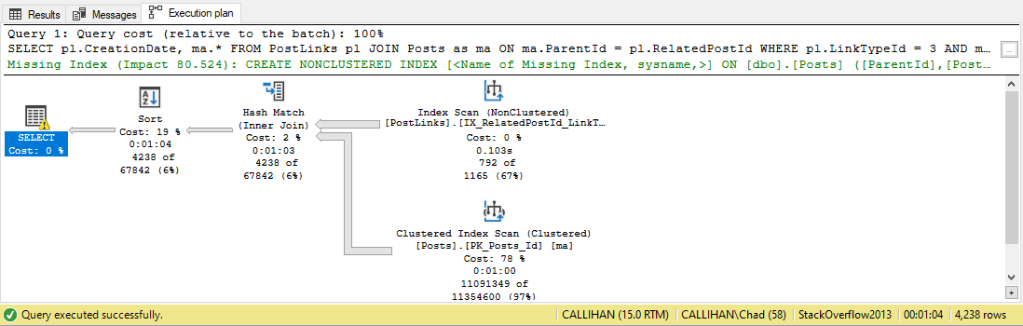

Our new index is used to scan for results but not much changed with our reads and execution times.
The Big One
We still have that same suggested index so let’s switch gears and do some work for the Posts table.
Instead of adding an index that includes the entire table as “suggested,” let’s stick with the columns involved in the JOIN (ParentId) and WHERE clause (PostTypeId).
CREATE INDEX IX_ParentID_PostTypeId ON Posts (
ParentId
,PostTypeId
);
We can run the query again and…
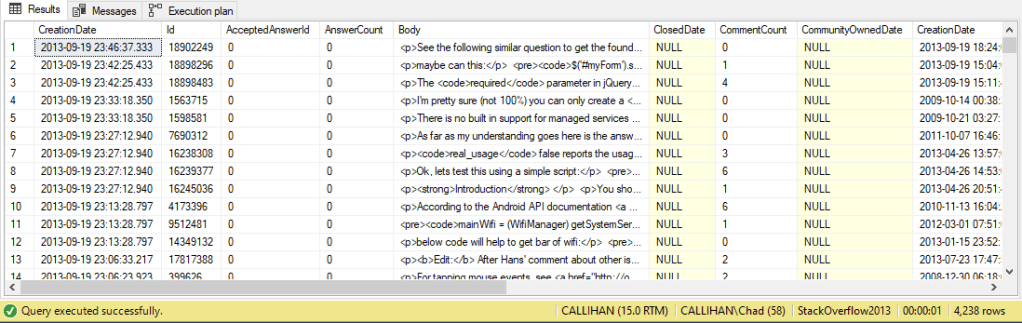
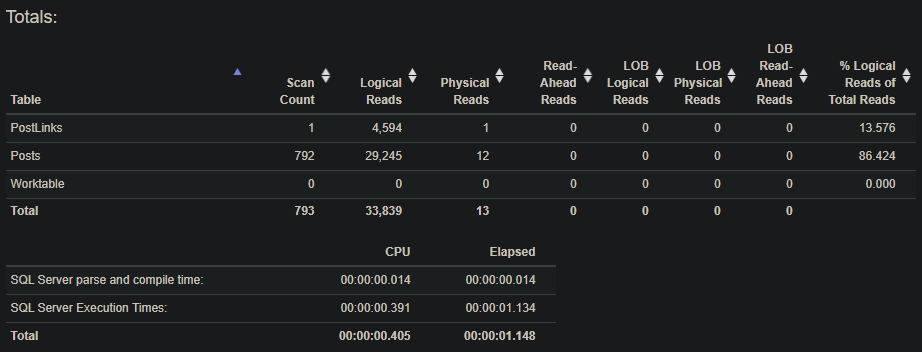
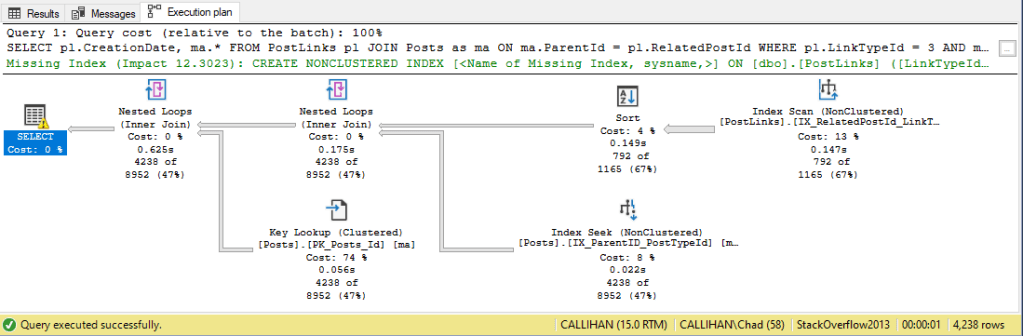
Now we’re getting somewhere. We made significant progress as our query only takes about a second to run.
Finishing Touches?
We still have a yellow exclamation point for a memory grant issue:
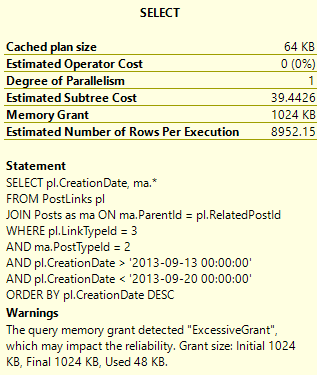
Also, we still have a scan on PostLinks and a Sort operator that I think we can eliminate.
If we look at the suggested index for PostLinks, we find that this suggestion might have a good point. We only need to INCLUDE RelatedPostId rather than specifying it as an index key column as we tried above. Let’s create this index for the PostLinks table:

CREATE INDEX IX_LinkTypeId_CreationDate_Include_RelatedPostId ON PostLinks (
LinkTypeId
,CreationDate
) INCLUDE (RelatedPostId);
When we run our query one final time:
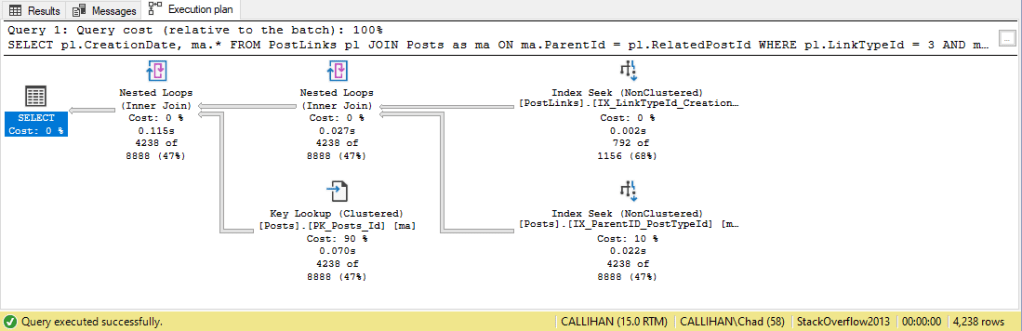
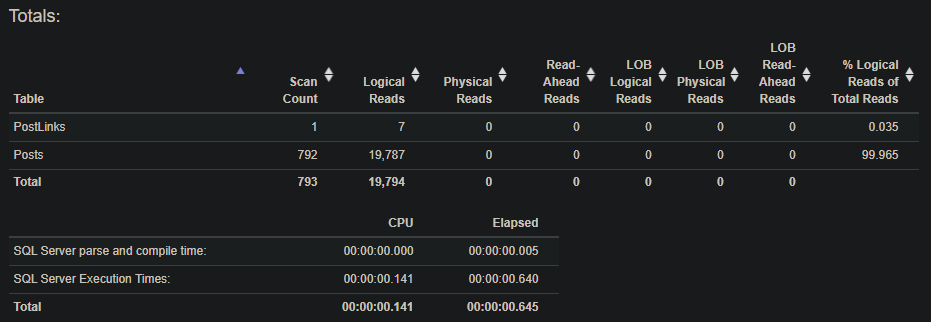
No more memory grant warning or Sort and our initial scans are now seeks. I’ll take it.
With two indexes, we took our query from an execution time of about a minute to an execution time of about a second. We went from over 4 million reads to just under 20k. I’d call that a success.
Thanks for reading!
