
When checking for the existence of a value or values in a table, typically, the whole table does not need to be read. The goal is to obtain more of a true or false answer, whether a criteria is met or not. If the criteria is met with the first few records then there’s no need to read on. Nonetheless, you may come across scripts written to unnecessarily retrieve the complete count of a value in a table. Let’s compare the performance difference between using COUNT(*) and using “IF EXISTS” when checking a table for values.
Heart of it All
Let’s start with a check to see if we have more than one user with a location of Ohio in the StackOverflow2013 database. The first query will use “IF (SELECT COUNT(*)…” and the second query will use “IF EXISTS…” for our checks.
Let’s click the “Include Actual Execution Plan” button in SSMS and also run the following so we can check some read information:
SET STATISTICS IO ON;
Now we’ll run these queries:
IF (SELECT COUNT(*) FROM Users WHERE Location = 'Ohio') > 1
PRINT 'Users from Ohio';
ELSE
PRINT 'No Users from Ohio';
IF EXISTS(SELECT * FROM Users WHERE Location = 'Ohio')
PRINT 'Users from Ohio';
ELSE
PRINT 'No Users from Ohio';

We can see the plans are very different. Comparing the query cost, we see the first query took it all with 100% while query 2 was at 0%.
What if we want to compare reads? Let’s click the Messages tab and see what differences we find there.

The first query had 30276 logical reads compared to the second query which only had 14.
Give Me a Boost
Going back to our view of the execution plans, you may have noticed an index recommendation. I don’t have any indexes at the moment so let’s change that. We’ll go with the index on Location.
CREATE INDEX [Location] ON Users (Location);
Let’s run our queries one more time and compare our query costs and logical reads,
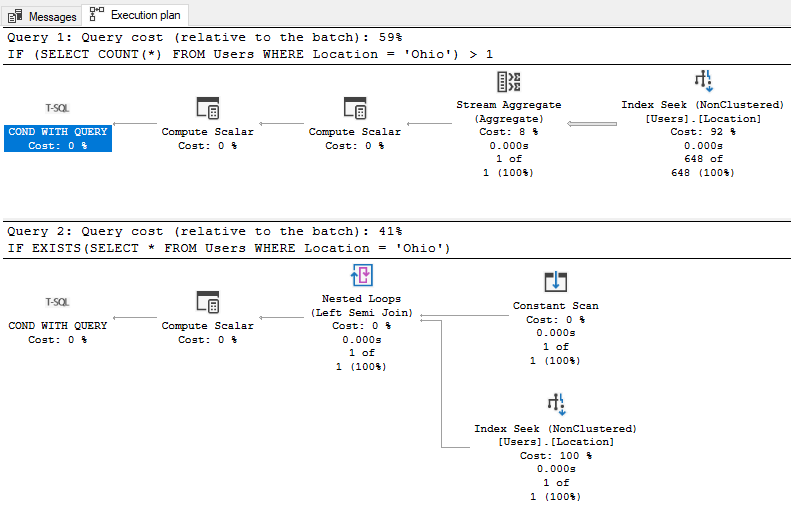

The new index helped both queries but the query with “IF EXISTS” is still more efficient.
Thanks for reading!

Hi, queries not equals
IF (SELECT COUNT(*) FROM Users WHERE Location = ‘Ohio’) > 0
and execution plans will be equal
LikeLike