
I’ve had some projects in the past that involved using Python to load data in SQL Server. It wasn’t unbearably slow, but it seemed like a process that could be faster. For that reason, a recent SQL Server blog post about bulk loading data with Python caught my eye. I decided to test out the new mssql-python 1.4.0 mentioned in that post and see how much of an impact it would make on loading speed.
The Old Way
Let’s start out with the “old” way. For our example, we want to read a CSV file of 100,000 comic test data records, build a list of rows, and load them into our database. We can run this script to accomplish that:
import pyodbcimport csvimport timeconn = pyodbc.connect( "DRIVER={ODBC Driver 18 for SQL Server};" "SERVER=SERVER_NAME;" "DATABASE=DATABASE_NAME;" "Encrypt=yes;" "TrustServerCertificate=yes;" "Trusted_Connection=yes;")cursor = conn.cursor()with open("CSV_FILE_PATH", newline="", encoding="utf-8") as f: reader = csv.reader(f) next(reader) rows = [(int(row[0]), row[1], row[2]) for row in reader]start = time.time()cursor.executemany( "INSERT INTO Comics (Id, ComicName, ComicPublisher) VALUES (?, ?, ?)", rows)conn.commit()elapsed = time.time() - startprint(f"Loaded {len(rows)} rows in {elapsed:.2f}s")
When this script completes on my machine, we can see our 100,000 records get loaded successfully in ~10 seconds.
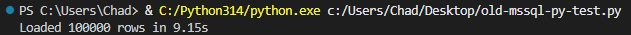
It could be worse. It could also be better. Which leads us to…
The New Way
Now let’s try the “new” way. With the new mssql-python 1.4.0, we can now utilize bulk copy (BCP), which should speed things up quite a bit. Let’s find out how much by running this script:
import mssql_pythonimport csvimport timeconn = mssql_python.connect( "Server=SERVER_NAME;" "Database=DATABASE_NAME;" "Encrypt=yes;" "TrustServerCertificate=yes;" "Trusted_Connection=yes;")cursor = conn.cursor()with open("CSV_FILE_PATH", newline="", encoding="utf-8") as f: reader = csv.reader(f) next(reader) rows = [(int(row[0]), row[1], row[2]) for row in reader]start = time.time()result = cursor.bulkcopy("dbo.Comics", rows)elapsed = time.time() - startprint(f"Loaded {result['rows_copied']} rows in {elapsed:.2f}s")cursor.close()conn.close()
Instead of taking around 10 seconds, our data is loaded in under a second.
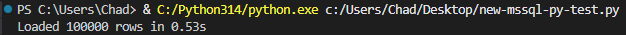
As advertised, that’s quite the improvement.
See for Yourself
If you’re doing any bulk data loading into SQL Server by using Python, get the latest version by running the following:
pip install --upgrade mssql-python
And get a nice boost in loading speed.
Thanks for reading!

One thought on “Bulk Loading Data with mssql-python”