
Have you ever needed to delete duplicate records from a table? If there is only one duplicate in a table then simply running something like DELETE FROM Table WHERE ID = @DupRecord will do the trick. What happens when the problem is found after multiple records are duplicated? Will tracking them all down be more time consuming? Here are a few different options for quickly clearing out duplicate records.
Ready to Believe in Good
Let’s setup test data with cities appearing in DC Comics. We’ll include duplicates and triplicates for our test:
CREATE TABLE DC_City (
CityId INT IDENTITY(1, 1) PRIMARY KEY
,CityName VARCHAR(100) NOT NULL
,StateID INT NOT NULL
);
GO
INSERT INTO DC_City
VALUES ('Gotham City',1),
('Smallville',2),
('Metropolis',3),
('Keystone City',2),
('Coast City',4),
('Bludhaven',1),
('Amnesty Bay',5),
('Midway City',6),
('Coast City',4),
('Metropolis',3),
('Gotham City',1),
('Gotham City',1),
('Keystone City',2),
('Amnesty Bay',5);
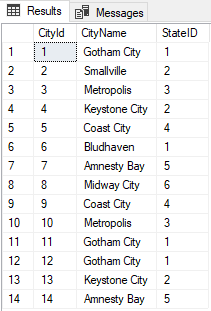
Creating and populating the DC_City table gives us:
SELECT * FROM DC_City;
GO
Identify Duplicates
We know we have duplicates and triplicates because we just inserted them. How would you check for these issues in a real world scenario? One option is to use GROUP BY to get the count of records. We can run the following:
SELECT CityName, StateID, COUNT(*) as 'CityCount'
FROM DC_City
GROUP BY CityName, StateID;
GO
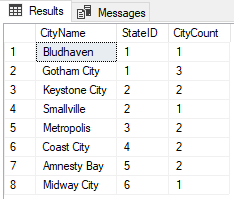
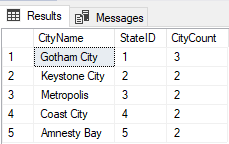
The result shows us that we have 3 Gotham City records and multiple other records duplicated. In our case, we don’t care to see records that only exist in the table once. If we only want to see records that exist more than once then we can add “HAVING COUNT(*) > 1” to the end:
SELECT CityName,StateID, COUNT(*) as 'CityCount'
FROM DC_City
GROUP BY CityName, StateID
HAVING COUNT(*) > 1;
GO
Remove with CTE
It’s time to clean up our table and get back to one record per city. We can accomplish this task by using a CTE, assigning row numbers, and deleting where the row number is greater than 1.
WITH CTEDup AS (
SELECT ROW_NUMBER() OVER(PARTITION BY CityName,StateID ORDER BY CityID) AS RowNbr
FROM DC_City
)
DELETE
FROM CTEDup
WHERE RowNbr > 1;
GO
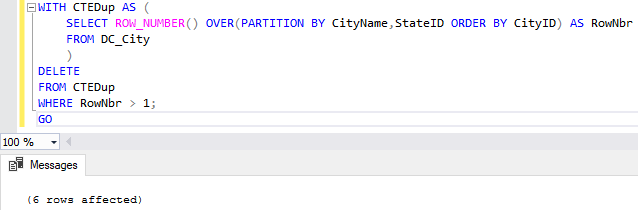
We’re ordering by CityID so we will keep the oldest records.
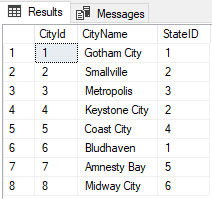
If the recent records were to be kept, the CityID could be ordered DESC.

Remove with MAX/MIN
MAX and MIN functions can also be used to remove duplicates. Using our original data, we can remove duplicates and keep the originals by using MIN:
DELETE
FROM DC_City
WHERE CityId NOT IN (
SELECT MIN(CityID) AS MaxCityID
FROM DC_City
GROUP BY CityName, StateID
);
GO
If we want the recently entered records, we can use MAX:
DELETE
FROM DC_City
WHERE CityId NOT IN (
SELECT MAX(CityID) AS MaxCityID
FROM DC_City
GROUP BY CityName, StateID
);
GO
Robin, You’ve Done it Again
As always, test and verify what you can before deleting duplicate records. You may clean up one table but find that other tables need work to match the corrections.

Thanks for reading!

One thought on “Deleting Duplicate Records”